
What is Reactive Programming? Server-side Reactive Programming
Reactive programming is a software paradigm based on asynchronous data streams and real-time event-based processing. It means that operations do not wait for each other to complete synchronously. It allows for non-blocking operations and allows for the execution of other operations asynchronously in real-time by observing events. Reactive programming implements events and asynchronous execution by monitoring the execution of other processes at runtime.
As we have defined it, we can continue with a more comprehensive explanation of the process and subsequent concepts that lead to understanding reactive programming.
Many modern applications today require the ability to handle a large number of concurrent/simultaneous requests. Therefore, traditional methods are insufficient for handling these operations. We need to move towards the principle of developing software by using hardware in the most efficient way, which has been a part of software engineering interests for a long time. Server-side Reactive programming is a way to improve the performance and scalability of web applications or server-side applications. This structure enables server-side applications to handle multiple requests asynchronously, improve performance, increase scalability and handle high user traffic.
Nowadays, microservices, cloud-native applications and distributed systems are quite common, and it is important to use resources more efficiently and to be responsive with low latency. Reactive programming provides a solution to these issues by allowing for non-blocking operations and real-time event-based execution. This allows to more efficient and responsive system.
Terminology
Asynchronous: It refers to the ability to perform a task without waiting for its result and continuing to perform other tasks simultaneously.
Data Stream: A series of events that occur sequentially over time. Streams give us signals such as values, errors, and completion.
Backpressure: A concept used to ensure compatibility between the speed of data flow and processing capacity.
Observable: An object type that tracks variable data or events.
Observer: An object that subscribes to an Observable to listen to data or events.
Event: Data or occurrence emitted by an Observable and listened by an Observer.
Reactive programming progresses by observing and listening to events and reacting to them, which is possible with the Observer Design Pattern.
What does it mean Backpressure?
Backpressure refers to the ability to control the rate at which data is processed in a system. When the system receives more data than it can handle, it can signal to the source to slow down or regulate the flow of data. This is an important feature for maintaining a stable system and is one of the advantages of reactive programming.

Imperative — Traditional Programming
Imperative programming, also known as traditional or synchronous programming, is a programming paradigm in which the programmer explicitly tells the computer what steps to take to solve a problem. In this approach, requests are handled by assigning a separate thread to each request in a thread pool. However, the capacity of the thread pool limits the number of requests that can be handled simultaneously. This method results in each thread being blocked when it encounters an I/O operation, leading to waiting and increased resource usage. Circuit breakers can be used to mitigate some of these issues, but they are not always sufficient.
Synchronous and Blocking structure can also affect performance when there is a high number of requests. Additionally, this approach does not optimize the use of system resources as new instances may be required to handle a high traffic, which can be costly. Imperative programming also lacks support for backpressure mechanisms, which can prevent system failures in case of sudden load increases.
General characteristics of traditional imperative programming applications:
- Synchronous and Blocking → Requests are processed synchronously and blocking. When a request is made, a thread is assigned to it and waits for any I/O operation to complete before returning a response. The thread remains blocked for other tasks and can return a response once the operation is completed.
- One thread per request → Allocating one thread per request also limits the number of incoming requests. The system can only handle as many requests as the size of the thread pool. Additionally, a large number of requests can affect performance.
- Poor utilization of system resources → In synchronous and blocking mode, to handle a certain number of requests in high traffic, new instances are required. This is a costly operation in terms of resource usage.
- Lack of support for backpressure mechanism → If there is a sudden increase in requests, server or client interruptions may occur. After that, users cannot access the application. We will discuss backpressure in more detail, but it can be described as a mechanism that prevents interruptions in the system in case of sudden load increases.
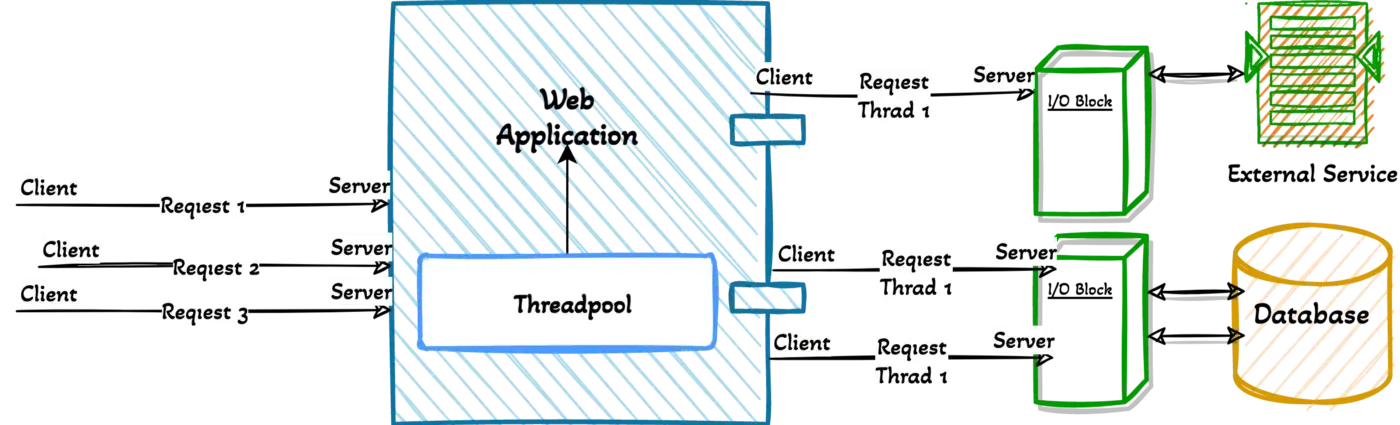
Even though there are various solution methods in every language, they can get stuck, face difficulties, or produce complex solutions in certain points.
Each thread consumes a certain amount of memory. High memory sizes are required for good performance in applications under high traffic. Horizontal scaling can be done with structures like Kubernetes. This method is currently one of the good solutions and will continue to be used in the future, however, creating new instances with each traffic increase can also create other problems in terms of cost and complexity.
Taking into account the costs and scaling problems, each instance has a cost and as engineers, we tend to do more with less. To solve these types of problems and produce better results, we can achieve more effective scalability with less memory usage and therefore less instances.
Reactive programming also aims to process requests by using asynchronous and non-blocking methods, allowing for more requests to be processed with fewer thread pools.
Is imperative programming dying?
It is not appropriate to look at every new technological development as killing off the old one. The answer is no. There are many points where the traditional method is sufficient when considering needs. Most small and medium-sized applications can still work efficiently with this method.
Diving into the Depths of Reactive Programming
Reactive programming is not a new but newly popular programming paradigm.
- It is tailored to improve asynchronous and non-blocking operations. It creates data flow through event/message driven streams.
- Reactive programming is not the same as (!=) Functional Programming. You can create great things by combining Reactive and Functional Programming.
- Backpressure support is available in data streams.
- It offers predictable response times due to its asynchronous and non-blocking structure.
- It offers better use of system resources. Threads will not be blocked and the application will be able to serve more users effectively with less threads. I can listen to music and write this blog post simultaneously without blocking:))
How does Reactive Programming work?
In reactive programming, the key is to manage data using event-based streams. Events, messages, calls, and even errors are transmitted through a data stream. With reactive programming, these flows are constantly observed and directly respond to any value changes, performing the next operation.
When programming an application, you should create data flows from anything and everything: user actions, HTTP requests, received messages, messages to be sent, notifications, changes in a variable, caching events, database operations; you can say that anything that can change or occur.
In reactive programming, an event or message is created for each result obtained from the data source. The data source can be an external service, a database, or a file. If the data source completes or an error is received, an event or message is created. So in both cases, we have an event present.
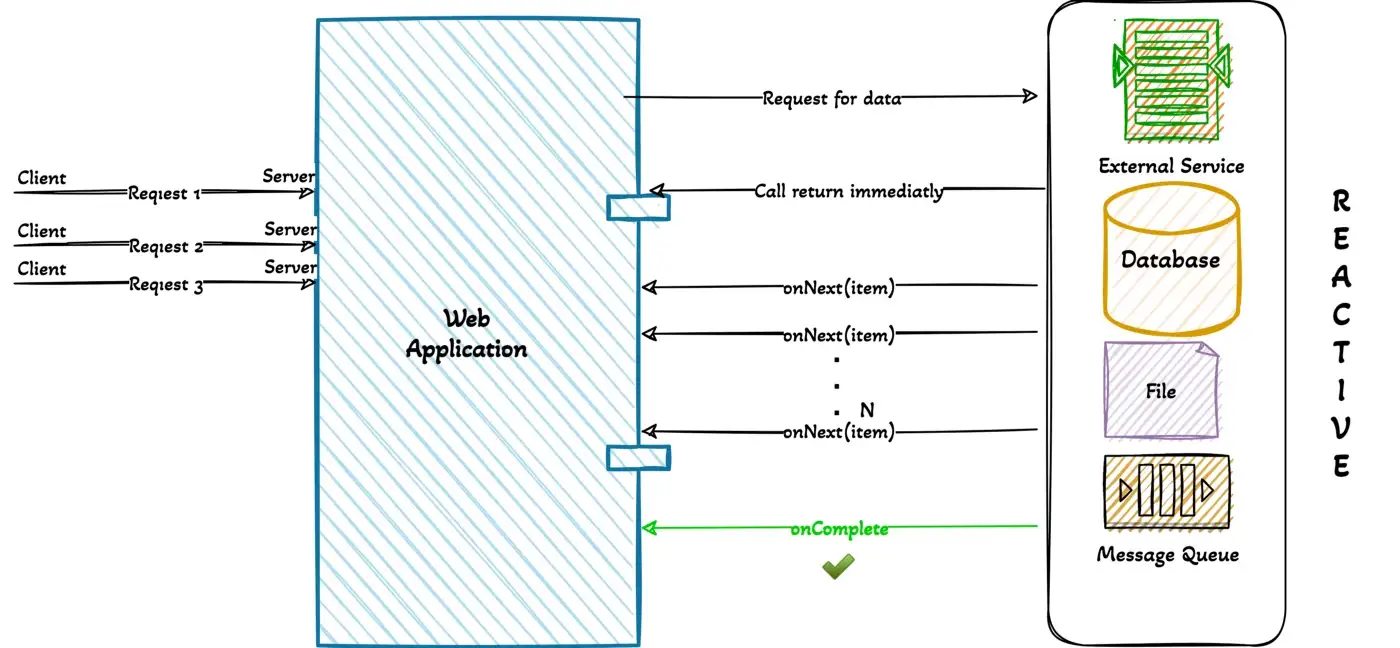
When a query is made to the database, the service immediately returns and the data is pushed through the stream as soon as it is ready. An event is created for each data element (item). The data stream is completed with onComplete.
What happens when an error occurs?
Every event or message that occurs in the stream corresponds to an event or message. Therefore, errors that occur also occur as events.
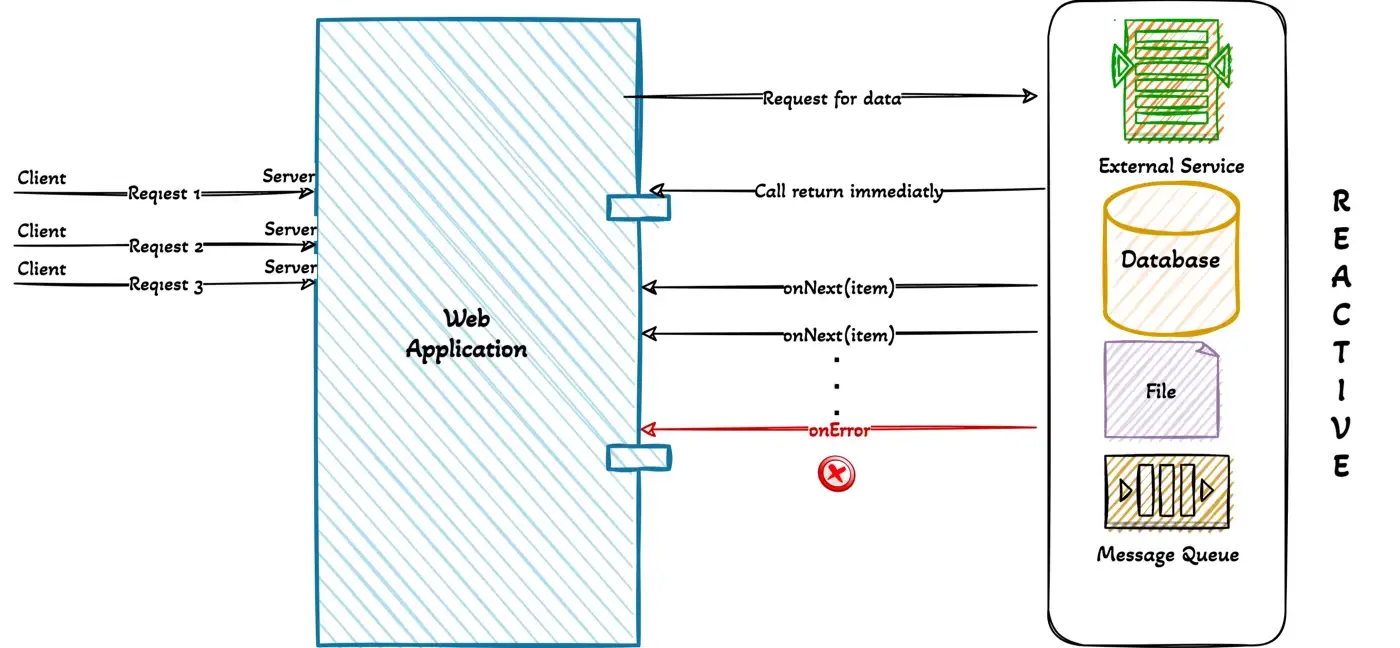
When fetching items, if an error is encountered, it falls as an event to onError. We can also resolve how to handle the exception in the onError section.
When we query the database and there are no results, the onComplete event still occurs.
For registration, we send the registration request and if the call is quickly responded and successfully completed, we can understand this with the onComplete event.
- onNext, we can move on to the next item while streaming.
- onComplete indicates successful completion,
- onError indicates an error situation.
Backpressure Support
We have previously discussed the importance of backpressure in reactive programming and what it is, let's take a closer look at how it can be applied. For example, we have a client application that receives data from another service. The service can send events at a rate of 100x, while the client application can only process events at a rate of 20x. In this case, the client application may experience performance loss or even interruptions due to excessive load. With the help of backpressure, one of the best features of reactive programming, the client application can inform the server that it can only process data at a rate of 20x and the service will only send data at a rate of 20x. This way, the client can continue to work efficiently with the amount of load it can handle.
Processes can be managed in a similar way to lambda operations in stream APIs. So functional programming works well with reactive programming.
In which applications is it suitable? Where should I use it?
As the number of users and traffic increases, backend services also need to be able to perform reactive and asynchronous operations. This need leads us to the option of Reactive Programming. Netflix is a big player here as well, they have been converting their Java-based systems to the Reactive model for some time. They are able to handle heavy traffic asynchronously by using 'observable' layers within the system.
- IoT Applications: In a world where millions of sensors send data, asynchronous and non-blocking operations are exactly what is needed. The growing presence of sensors and IoT devices requires the ability to handle more traffic in real-time and asynchronously. This creates even more intense traffic, which can be handled without interruption using reactive programming. Therefore, IoT applications are one of the most commonly used areas for reactive programming.
- Data monitoring, logging applications: Reactive programming is often used for processing and visualizing log data. Applications that monitor and track user responses and movements, such as gaming and social media, use reactive programming for data processing and analysis.
- Batch Applications: In particular, applications that deal with bulk data benefit greatly from the non-blocking management of threads in an asynchronous manner in terms of performance and time/cost, and that's exactly why reactive programming is used.
Applications that require asynchronous and non-blocking execution, even if they don't need it, always have the option of reactive programming for good performance.
The Reactive Manifesto
The Reactive Manifesto is a document that defines the basic principles of reactive programming. When discussing reactive programming, it is impossible not to mention the Reactive Manifesto. The website reactivemanifesto.org has more information about it.
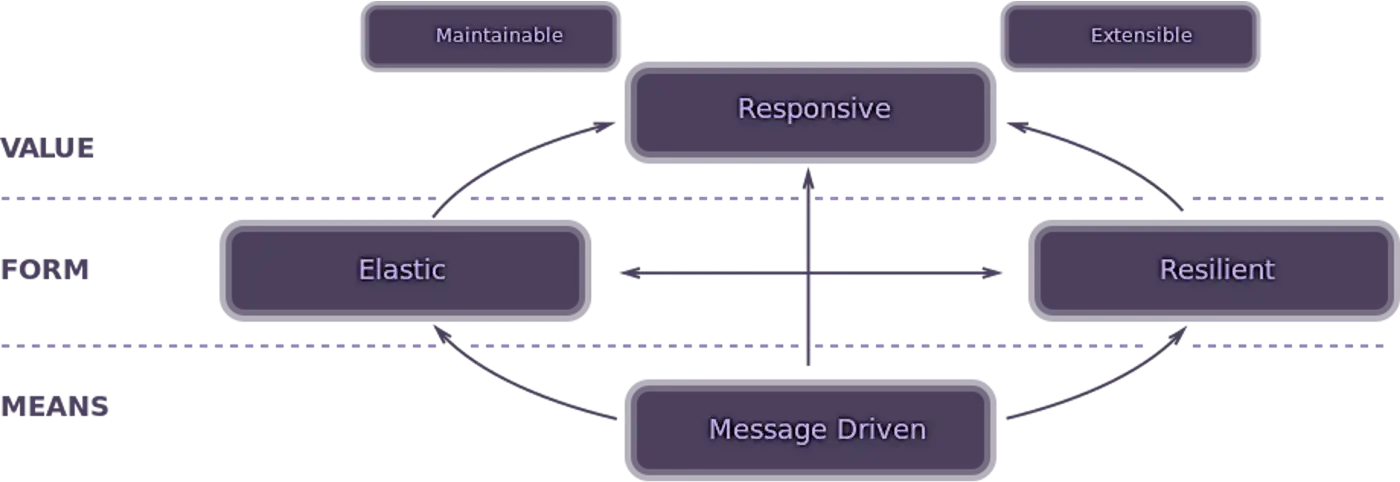
The manifesto advises us that reactive systems should be:
- Responsive: The system should respond in a timely manner. Responsive systems focus on providing fast and consistent response times to ensure consistent and stable service.
- Resilient: The system should continue to respond even when faced with problems. This means that the system should not experience interruptions. Problems and errors can be addressed by isolating components from each other and making each component resilient within itself. In this way, problems on one component do not affect the others, and the system can continue without interruption.
- Elastic: Reactive systems can respond to changes and maintain responsiveness under changing workloads. They can effectively use hardware resources to complete tasks in less time or at lower cost.
- Message-Driven: To create resilience, reactive systems can communicate between components using asynchronous message exchange.
Rx — Reactive eXtension
Rx stands for Reactive eXtensions and it is a shortened version of it. It provides library/API support for almost every language to enable reactive programming. It includes libraries that use observable streams and lambda-style operators to develop asynchronous and event-driven applications. It helps developers manage operations such as creating threads, synchronous and asynchronous, and concurrency without having to handle the details.
- Java: RxJava — JavaScript: RxJS — C#: Rx.NET,(Unity): UniRx
- Scala: RxScala — Clojure: RxClojure — C++: RxCpp — Lua: RxLua
- Go: RxGo — Ruby: Rx.rb — Python: RxPY — Groovy: RxGroovy
- Kotlin: RxKotlin — JRuby: RxJRuby — Swift: RxSwift
- PHP: RxPHP — Elixir: reaxive — Dart: RxDart …

You can find more on the official site: http://reactivex.io/
Understanding and explaining reactive programming is much harder than applying it. :)
This is the first article in a series on reactive programming. By following the other articles in the series, you can learn how to implement in server-side and better understand the concepts. Although it may be difficult to fully understand reactive programming at once, you can overcome this problem by practicing.
— Contact: gokhana.dev, Twitter, Linkedin, gokhana@mail.com
— Talk is cheap, show me code: GitHub
— 1:1 Superpeer